Model SEO
Claude SEO: Make Your Brand Easier For Cautious AI Answers To Evaluate
Identify whether Claude has enough transparent evidence to include your brand instead of safer competitors.
The job of Claude SEO
Claude SEO is about making your brand easier for a cautious answer to trust. A Claude-style response often rewards clarity, restraint, transparent claims, and enough context to avoid overrecommending the wrong option. That makes it especially useful for legal, healthcare-adjacent, finance, B2B software, local services, and any category where buyer risk matters. The goal is not to sound louder. The goal is to make the safer recommendation also be the accurate recommendation.
Claude is similar to the other models because it still needs category clarity, proof, and source support. The difference is how much weak proof can matter. If the page says "best in class" without evidence, or if the offer is broad enough to create confusion, Claude may prefer a more established or clearly documented competitor. Your action plan should reduce uncertainty: who the product is for, what it does, what it does not do, what proof exists, and what a buyer should verify.
How Claude is similar to the other models
Claude, ChatGPT, Gemini, Perplexity, Grok, and DeepSeek all need a coherent entity. They need to understand the business category, buyer type, offer, proof, and alternatives. If your website hides the category behind clever language, every model has to work harder. If your proof is scattered, every model has less confidence. If your reviews and citations describe old services, every model can produce stale or inaccurate answers.
The shared action is to build a clean evidence layer. Write the category plainly. Add FAQs that answer real buyer objections. Publish case studies or examples. Keep pricing, process, service areas, integrations, or product details current. Build comparison pages that explain fit honestly. These improvements help Claude, but they also help ChatGPT explain you, Gemini classify you, Perplexity cite you, Grok associate you with current discussion, and DeepSeek parse the offer.
How Claude is different
Claude is different because unsupported certainty can work against you. A page that is all hype and no proof may produce weaker Claude visibility than a page that carefully explains the right fit, limitations, and evidence. In trust-sensitive categories, that matters. Claude may avoid strong recommendations when credentials, safety details, customer proof, service scope, or implementation process are unclear. The more risk a buyer might feel, the more important transparent proof becomes.
Action step: audit your pages for claims that sound impressive but cannot be verified. Replace broad claims with precise statements. "We help med spas get more clients" is weaker than "We track whether AI answer systems mention a med spa for Botox, filler, laser, and trust prompts, then recommend content, review, and citation fixes." Precision gives Claude more to work with. Add proof under the claim, not three scrolls later.
Trust proof Claude can use
Claude-friendly proof includes case studies, customer examples, service credentials, author information, transparent methodology, limitations, implementation details, and clear next steps. For SaaS, that may mean pricing clarity, integration notes, security pages, onboarding expectations, and comparison pages. For local services, it may mean licenses, reviews, service-area details, before-and-after examples where appropriate, safety language, and a clear explanation of who performs the work.
The practical fix is to create a trust proof inventory. List the five strongest reasons a buyer should believe you. Then ask whether each reason exists on a crawlable page, in language a non-expert can understand, close to the claim it supports. If the proof is only in a sales deck, it is not helping Claude or any other AI platform. Move proof into public pages, summarize it clearly, and connect it to the buyer prompts you monitor.
Prompt patterns to monitor
Claude SEO should include trust prompts, risk prompts, comparison prompts, and fit prompts. A trust prompt asks whether a business is legitimate or safe. A risk prompt asks what to watch out for. A comparison prompt asks whether one option is better than another. A fit prompt asks which provider or product is best for a specific buyer. Claude may answer these prompts with more caution than a general product recommendation prompt, which makes them excellent diagnostic tests.
Action step: run prompts such as "is this company trustworthy," "what are the risks of choosing this service," "which option is best for a small team," and "brand versus competitor for regulated buyers." Capture whether Claude names you, whether it hedges, which competitors appear, and what proof it says matters. If the answer uses cautious language around your brand, do not ignore that. Translate the caution into a page, proof, or claim-clarity fix.
How to compare Claude with ChatGPT and Gemini
ChatGPT may be more comfortable synthesizing a broad recommendation from general category signals. Gemini may emphasize structured facts, entity consistency, and Google-visible information. Claude may apply a more careful filter to claims and buyer risk. If ChatGPT recommends you but Claude does not, the issue may not be awareness. It may be confidence. If Gemini understands your category but Claude hesitates, the issue may be proof and positioning rather than schema or entity clarity.
Action step: create a three-model diagnosis table. For each prompt, mark whether ChatGPT recommends, Gemini understands the category, and Claude trusts the recommendation. If ChatGPT and Gemini pass but Claude fails, rewrite trust pages, add case studies, tighten claims, and clarify limitations. If all three fail, start with category language and basic proof. If Claude is the only one recommending you, your trust content may be strong but your source and structured visibility may still need work.
How to compare Claude with Perplexity, Grok, and DeepSeek
Perplexity can show whether source proof exists. Grok can show whether current discussion supports the category. DeepSeek-style checks can show whether the offer is described directly enough. Claude brings a trust lens to all of those findings. A source can exist and still be weak proof. A social mention can be fresh and still not support a responsible recommendation.
Use Claude as the "should a careful buyer believe this?" check. If Perplexity cites a page but Claude still hesitates, improve the substance of that page. If Grok finds fresh discussion but Claude avoids recommending the brand, the discussion may not be credible enough. If DeepSeek understands the category but Claude does not recommend, your category language may be fine while your evidence is thin. The best action plan separates clarity problems from trust problems.
What to do when competitors win
When Claude recommends a competitor, look for safety, specificity, and proof advantages. The competitor may have more transparent pricing, clearer credentials, better case studies, more precise claims, stronger reviews, or a more detailed explanation of who the product is and is not for. Claude may also prefer competitors that avoid exaggerated marketing language. That does not mean your copy should become boring. It means your copy should be easier to verify.
Action step: build a competitor trust comparison. Compare your claims against competitor claims. For each claim, mark whether proof is visible, whether the page explains limits, whether the buyer fit is clear, and whether a cautious reader would know what to do next. Then fix the largest proof gap first. Do not publish fifty weak testimonials. Publish the three proof points that answer the objection behind the prompt.
What to measure after changes ship
Claude SEO metrics should include brand mention status, recommendation strength, hedge language, competitor mentions, trust objections surfaced, and answer accuracy. A useful improvement may be subtle. Claude may move from "consider researching this company further" to "this company may be a fit for teams that need X, especially if Y matters." That change is valuable because it means the model has more confidence in the fit.
Action step: save the exact language Claude uses before and after trust fixes. Track whether the answer becomes more specific, more accurate, and less competitor-led. If the model still hesitates, inspect whether the page needs more evidence, a clearer limitation, a customer example, or a third-party source. Claude SEO is not finished when the brand appears. It is finished when the answer can explain why the recommendation is appropriate.
The Claude SEO action plan
Start with one trust-sensitive prompt. Capture the answer. Highlight every cautious phrase. Turn each phrase into a question: what evidence would reduce this uncertainty? Then ship one fix. Add a case study, rewrite a claim, publish a methodology page, add credentials, clarify pricing, or create a comparison page that explains the right fit. Rerun the prompt after the fix is live.
The longer-term workflow is to pair Claude monitoring with broader model monitoring. ChatGPT shows synthesis, Gemini shows structured/category understanding, Perplexity shows sources, Grok shows current discussion, and DeepSeek shows direct wording. Claude adds the trust filter. If your brand can pass that filter, the rest of your AI SEO work usually becomes more durable.
Build the baseline Claude report
The baseline report should be simple enough that a founder, marketing lead, or agency account manager can understand it in one sitting. Start with the exact prompt: "Is this med spa a trustworthy choice for Botox?". Save the AI platform or signal, scan date, brand mention status, competitors surfaced, answer summary, and first recommended action. Then add one short note explaining why this answer matters commercially. The report should not bury the lead. It should answer whether Claude recommends the brand, recommends a competitor, or avoids naming a clear option.
For Claude, the baseline should also include the specific signal this page is built around: careful claims, case studies, transparent positioning, proof pages, risk-aware language, and content that avoids hype. If the answer is weak, connect that weakness to a business action. The action cannot be "improve SEO" or "make better content." It should be specific enough for a team to assign: rewrite the category paragraph, publish a comparison page, add FAQ coverage, request reviews mentioning the use case, update a profile, fix stale facts, or create a source-worthy guide.
Create the monthly Claude action backlog
The monthly backlog turns the article into a workflow. Put every finding into one of four statuses: do now, do this month, monitor, or not worth it yet. Do-now tasks are fixes that remove obvious confusion from high-intent prompts. This-month tasks are credibility, source, review, or comparison improvements that need more time. Monitor tasks are changes that may matter but are not urgent. Not-worth-it-yet tasks protect the team from chasing every small answer variation.
For Claude, the first backlog usually starts with clarify claims, add trust proof, publish case studies, use transparent positioning. Add an owner, expected impact, difficulty, and next scan date. This makes AI SEO feel less like a mystery and more like a marketing operating system. The team knows what changed, why it changed, and when to check whether it worked. Without that backlog, a long AI visibility report can become another interesting document that no one acts on.
Turn Claude insights into team assignments
Different findings belong to different owners. Category clarity belongs to the website or product marketing owner. Case studies and proof belong to customer marketing or sales. Reviews belong to customer success or operations. Citation gaps may belong to PR, partnerships, SEO, or an agency. Structured facts and schema may belong to the web team. Fresh public discussion may belong to content, founder-led marketing, or social. The dashboard should make the handoff obvious.
Action step: after a Claude scan, write one task in plain language and assign it to the person who can actually ship it. A good task says what page, proof point, source, profile, or comparison needs to change. It also says which prompt the task is expected to improve. That prompt link matters because it prevents random marketing activity. The team can return to the same question later and see whether the answer changed.
Avoid false precision with Claude
AI answers vary, so the report should avoid pretending that one run is a permanent ranking. The professional way to frame the result is as prompt evidence captured at a specific time. That evidence is still valuable. It shows what the answer said, which competitors appeared, and what gaps were visible. But it should not be sold as a guaranteed ranking position or a private view into user behavior. Conservative language makes the product more credible, especially with technical buyers.
For Claude, use labels like visible, weak, missing, competitor-led, directional, and needs review. Do not show internal confidence scores to customers. Instead, explain what the evidence supports. If the result depends on indirect or source-specific signals, say so. If citations or sources are available, show them. If they are not, explain that the recommendation is based on the saved answer and observed content gaps. This keeps the offer strong without overclaiming.
Use Claude findings in sales and content planning
The best AI SEO findings should not stay trapped inside the marketing team. If Claude misunderstands the offer, sales probably hears the same confusion from prospects. If Claude recommends a competitor because that competitor explains a use case better, the content team has a page to build and the sales team has an objection to prepare for. If Claude surfaces a proof gap, customer marketing has a review, testimonial, case study, or example to collect.
Action step: turn the monthly Claude report into three internal notes. First, the buyer question: what did the customer ask? Second, the market signal: who did the answer trust and why? Third, the next asset: what page, proof point, source, script, or comparison would make the next answer stronger? This keeps AI visibility connected to revenue work instead of becoming another isolated analytics dashboard.
What success looks like for Claude
Success is not just more content or a prettier dashboard. Success is when the answer becomes more useful for the buyer and more favorable to the brand. That can mean the brand moves from missing to mentioned, from mentioned to recommended, from inaccurately described to accurately described, or from competitor-led to balanced. It can also mean the model starts using stronger proof language, names fewer irrelevant competitors, or reflects the updated positioning after implementation.
The long-term scorecard should track brand mention rate, recommendation status, competitor count, citation or source coverage when available, answer accuracy, and action completion. Pair those metrics with before-and-after evidence. The best monthly report for Claude should end with a clear sentence: here is what changed, here is why it matters, and here is the next fix most likely to make the business easier for AI to understand and recommend.
Prompt-Specific Field Note
Run the same prompt against Claude SEO and two related models, then compare whether the answer misses the brand for clarity, proof, source, or category reasons.
Use this as a diagnostic result, not a guaranteed ranking claim. The scan should show what the answer said at a specific time.
Next supporting fixes: Clarify claims, Add trust proof, Publish case studies.
Sample Prompt Result
Redacted sample report layout. Replace with live scan evidence before using as a customer case study.
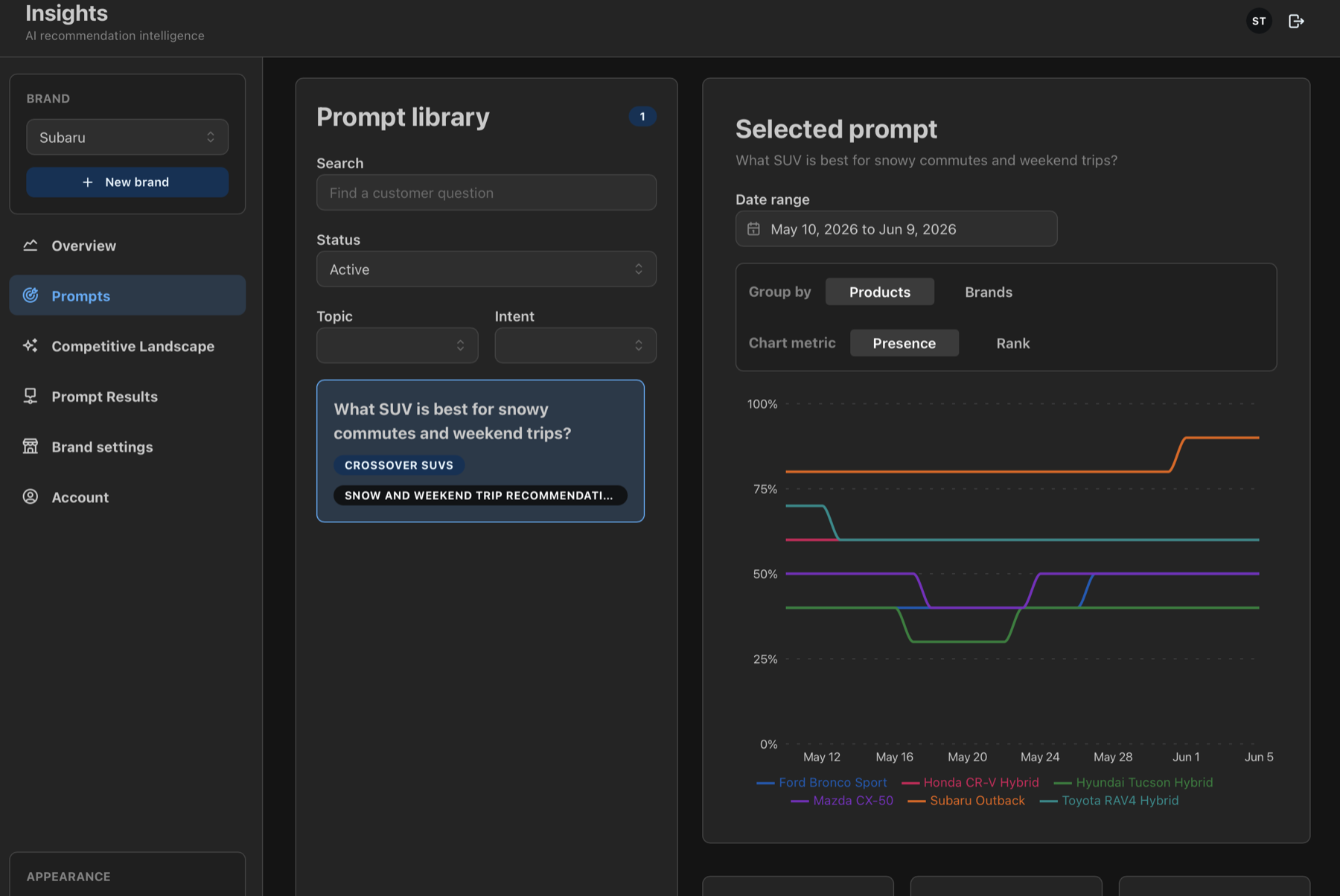
Example Insights Screenshot
This sample view shows the kind of prompt trend and answer evidence a team should review before deciding what to fix for Claude SEO.
How We Test AI Visibility
Use a question close to revenue, not a generic keyword.
Save the platform or signal, date, status, competitors, and citation/source notes.
Separate direct prompt evidence from directional or indirect signals.
Turn the result into a content, proof, review, citation, or positioning action.
For Claude SEO, the useful question is not whether one answer looked good once. The useful question is whether the same buyer prompt can be checked, reviewed, improved, and checked again after the team ships a clearer page, stronger proof, or better source coverage.
What A Useful Report Includes
The exact buyer question tested.
The model or signal reviewed.
When the evidence was captured.
Visible, weak, missing, or competitor-led.
Brands or alternatives named instead.
Citations, reviews, or pages to improve.
The first fix to test before the next run.
What To Fix First
- Clarify claims
- Add trust proof
- Publish case studies
- Use transparent positioning
Frequently Asked Questions
What does Claude tend to need?
Claude-style answers often reward careful claims, transparent proof, and clear context about who the product is for.
How can I improve for Claude?
Clarify claims, publish case studies, add proof pages, and make buyer fit easy to understand.